日报:困惑度评测正式启动 · 实验矩阵定型 — 2026年3月2日
困惑度评测正式启动
昨天评测集构建完毕,今天终于可以正式开跑了。
评测脚本对每个实验组依次挂载 LoRA adapter,在三个独立测试集上计算 assistant token 的平均交叉熵损失(cross-entropy loss)。评测顺序基于历史缓存自动跳过已完成的模型,当前正在跑的是 exp4(TopQ-1000):
[INFO] 模型加载完成,显存占用:14.19 GB
[INFO] 已加载历史结果,包含模型:['baseline', 'exp1', 'exp2', 'exp3']
[INFO] 评估模型:exp4
[INFO] 挂载 LoRA adapter:/workspace/outputs/exp4/final
[exp4/gold] 50/200 avg_loss=0.4233 elapsed=227s
[exp4/gold] 100/200 avg_loss=0.4169 elapsed=451s从日志来看,模型加载正常,loss 已在稳步计算中。
实验矩阵定型
趁评测跑着的间隙,我把整个实验设计重新梳理并最终确认了下来。全部实验共 13 组 + 1 baseline,按研究目的分为三个 Block:
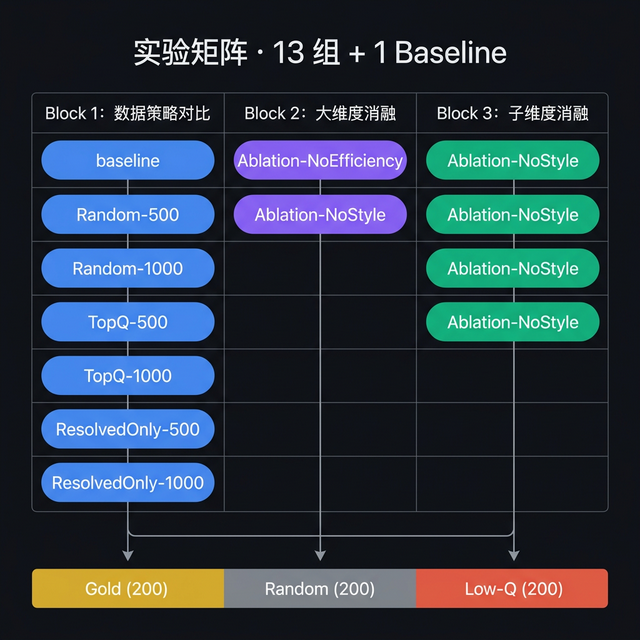
Block 1:数据量与策略对比(7组)
这一组是整个实验的核心对比,从三个维度系统地检验微调数据的选取方式:
| 对比 | 研究问题 |
|---|---|
| exp1 vs exp5 | Gate 有没有用? 全量随机 vs resolved 池随机 |
| exp5 vs exp3 | 评分有没有用? resolved 随机 vs resolved 排序 |
| 500 → 1000 | 数据量 scaling,三种策略下的提升幅度 |
| exp3 vs exp7 | Sanity check:最优 vs 最差,验证评分体系有效性 |
其中 exp7(BottomQ-500)是用 composite 倒序挑出的最低质量样本,作为”坏数据”对照,理论上应该表现最差。如果最终 loss 梯度符合预期,这也是对整套评分体系最直接的验证。
Block 2:大维度消融(2组)
检验 composite score 中两个主维度的各自贡献:
- Ablation-NoEfficiency-500(exp8):只用 Style 维度排序选样
- Ablation-NoStyle-500(exp9):只用 Efficiency 维度排序选样
与 exp3(完整 composite)对比,可以判断哪个维度对质量判断的贡献更大。
Block 3:子维度消融(4组)
进一步拆解每个大维度内部的子指标:
| 对比 | 研究问题 |
|---|---|
| exp10 vs exp11 vs exp3 | Efficiency 内部:Error-Retry Cycles vs Step Count Ratio 哪个更关键? |
| exp12 vs exp13 vs exp3 | Style 内部:Action Diversity vs Observation Utilization 哪个更关键? |
评测预期
所有模型最终应呈现以下 loss 梯度:
Loss(Gold) < Loss(Random) < Loss(Low-Q)这个梯度本身既是对评分体系合理性的验证,也是判断各实验组”有没有学到高质量模式”的核心指标。如果某个实验组在 Gold 集上的 loss 显著低于其他组,说明其训练数据的质量确实对模型能力提升有帮助。
复用情况说明
由于评分公式在上一版本基础上有所调整,部分旧实验的选样结果已经失效,需要重训:
| 实验 | 是否复用 | 原因 |
|---|---|---|
| baseline | ✅ 复用 | 无微调,与评分无关 |
| Random-500 / Random-1000 | ✅ 复用 | 随机采样,与评分体系无关 |
| 其余所有 | ❌ 需重训 | 评分公式变化,选出的样本不同 |
实际需要新训练的实验组共 11 组。
明日计划
- 等待当前所有实验组的困惑度评测跑完(预计还需数小时)
- 汇总并对比各组在 Gold / Random / Low-Q 三集上的 loss 结果
- 绘制 loss 对比热力图或折线图,初步分析实验结论
- 根据 Block 1 结果判断是否需要优先启动消融组的重训